We are still early in figuring out how to build software effectively with AI. Our architectures, toolchains, and deployment pipelines emerged from decades of humans writing code. The shift to AI-generated code is fundamental enough to require deep rethinking. We are nibbling around the edges, adding AI tactically, but the core methodology remains unchanged. Atomic Programming is my exploration into what a truly AI-centered approach might be.
The foundation is Hypercompetence — that golden zone where LLMs generate useful code at a stunning pace. Stay in the zone, and you get superhuman velocity. Drift out, and you get the circular monologue, the zombie behavior, bugs moving from one place to another.
So the question becomes: how do you keep LLMs at peak performance throughout the entire development process? It’s easy to get a fast start — the challenge is maintaining that pace all the way to production, building real software instead of demoware.
Why Atoms
My answer: decompose the system into atoms — small components, each scoped to fit comfortably within the LLM’s cognitive capacity. What makes atoms different from libraries, modules, or microservices is their purpose. We are not decomposing for reuse. Not for elegant abstractions. Not for decoupling, or team ownership boundaries, or scaling considerations. We are decomposing to manage the LLM’s cognitive load — and nothing else.
This leads to a surprising inversion. Traditional decomposition optimizes for DRY, for combining and recombining pieces like an alphabet making words. But chasing reuse means layering abstractions and decoupling components, which increases complexity, which pushes you out of the golden zone. Atoms flip the economics. They are so cheap to create that you spin up new ones rather than carefully recombining existing ones. By the same logic, coupling is fine — if three atoms are intertwined, throw them all away and rebuild all three. That is not a concern when creation costs minutes instead of days.
How It Works
What does this look like concretely? Atoms are small standalone servers — I write them in Go, and they talk to each other over HTTP. This matters because it means Claude Code can reach into the system with curl and jq, query real endpoints, and understand what already exists. Every atom supports GET /doc, returning a description of its API, so discovery is built in. As each atom comes online, it joins the partial system, which becomes rich context for building the next increment. And since we are not investing in elegant abstractions to decouple atoms from each other, the whole process compounds quickly. I explore the technical foundations in more detail in Web Primitives.
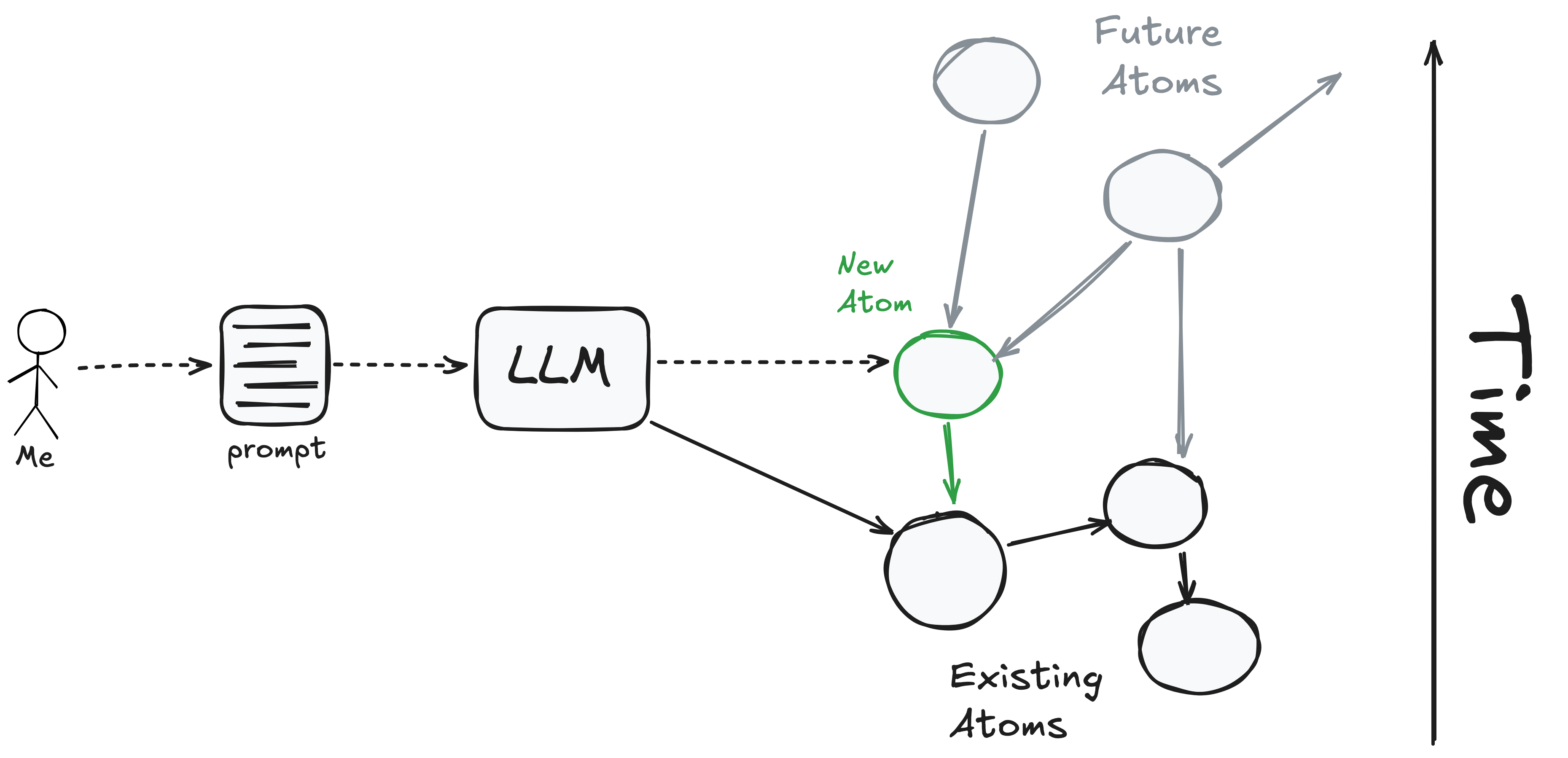
When I want to change an atom, I modify the prompt and rebuild — for the most part, I treat the code as immutable. The prompt is the source of truth; the code is just an artifact. The less the definition spills over into the artifact, the more leverage the prompt has. And because atoms are small in scope, the prompts are small too. I don’t need to provide detailed guidance — we are in the golden zone, after all. The problems are bounded. The tech stack is one LLMs are fluent in. I don’t dictate endpoint names or JSON structure; the LLM makes reasonable choices, and reasonable is good enough. Short prompts turn out to be surprisingly high leverage. Not having to craft and manage detailed specifications speeds up my own thinking dramatically.
This is where I am starting. To put these ideas to the test, I’m building Superpage in public — a product that addresses a need I personally feel, and a vehicle for reality-checking and refining Atomic Programming as I go. The principles are still taking shape, but the early results suggest something worth pursuing.